由于公司业务的需要,大量商业智能(BI)和神经网络识别云API产生的图片需要一个有效、可靠的存储,于是笔者和另外一位同事开启了ceph调研、测试、上线、运维的一系列工作,从刚开始的调研来看,ceph存储小文件的问题被很多人诟病,它的rados架构注定不能完成这样的任务,但是我们大胆使用了ceph进行10KB-2MB的海量小图片的存储,上线一个月以来,表现还可以
写在前面
松鼠哥的ceph专业课程上线啦!
面向新手同学,从0实战,全面入门ceph安装部署与运维,有需要的同学赶紧联系松鼠哥订购吧:
小文件存储是存储业内难以解决的痛点问题,在明确业务需求后,还要对技术方案进行调研和选型。
方案的选型
起初,我们在策划存储项目的时候考虑过几种方案,最开始是使用本地磁盘进行存储,显然,快速增长的数据量让服务器不堪重负,后来我们定期将图片打包寄存到亚马逊,但是成本真的太高,而且存上取下走网络真不太方便
我们请来了好多家存储公司来谈,杉岩、品高、联想等,由于各种原因,没有达成合作,我们还是坚持自己做,技术控制在自己手上才是最稳的;开源存储方案当然就选ceph,在第一版本中我们大胆使用了当时最新的大稳定版本ceph-12.2.5,经过一系列测试和性能调优,就拿到线上去用了
实践情况
我们使用的配置:
- 主要存储:磁盘柜子,每个磁盘柜有84个盘槽,插满10TB的HDD磁盘,一套集群两个磁盘柜子,总容量1.6PB
- 服务器:使用联想24盘位的机器,盘位上只插ssd磁盘做加速盘和db盘,每台设备内存256GB
- 网络:使用InfiniBand网卡,4036E的IB交换机,40Gbps的网络能力,开启巨帧模式
- osd配置:168个HDD的osd + 8个ssd的osd,ssd的osd承载了除了bucket.data池之外的全部存储池
1 | [tanweijie@ceph-52-201 ~]$ sudo ceph -s |
即使是出动两个磁盘柜子,达到PB级的容量,也只能扛住一个月的数据量;目前集群存放的图片数量为3311314090张,按照每个小时一个bucket来进行存放,在此配置情况下,集群写ops也很正常,超过40Kops,没有出现延时很高之类的情况
三十亿图片数据下集群情况
集群写入总量为86.66%时我们停止了写入,因为某些osd已经写入太多数据,一旦达到90%,有osd full的情况,集群将无法读写,不能冒险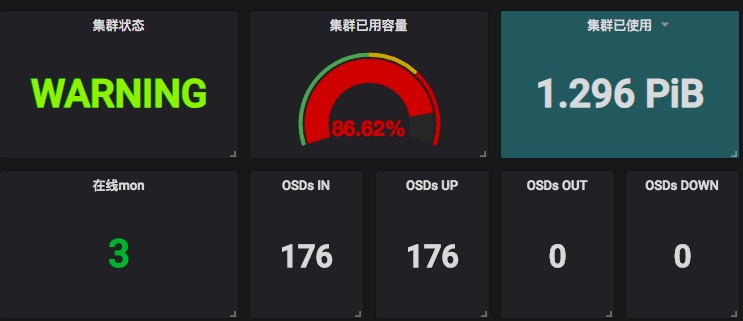
某些osd已经超过88%的容量,db分区占用的情况,明显看出ssd-osd的db占用了非常大的量,因为规划得好,即使用得这么满,slow分区也完全没有使用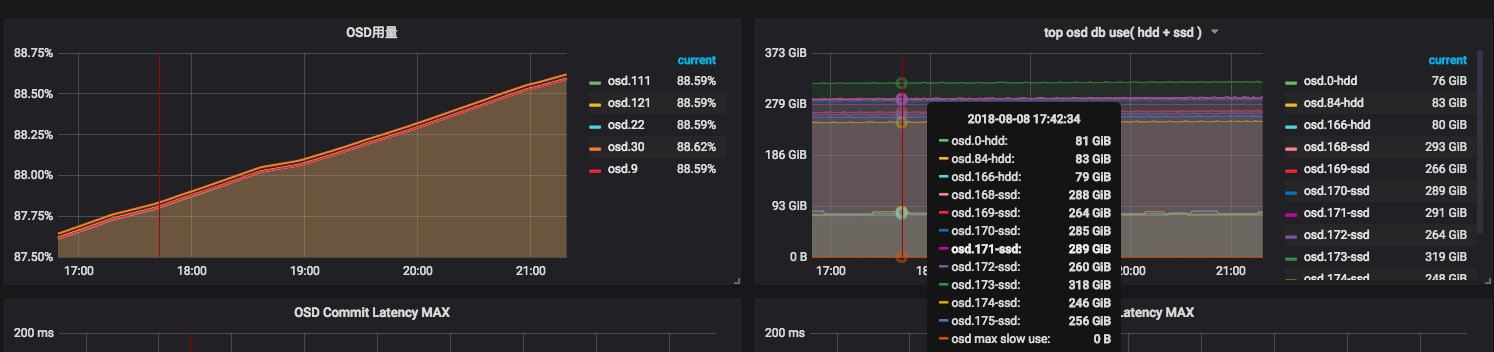
在集群切换之前,前端写入依然保持全速写入和读取,前端未反馈任何读写问题,看起来仍然工作顺利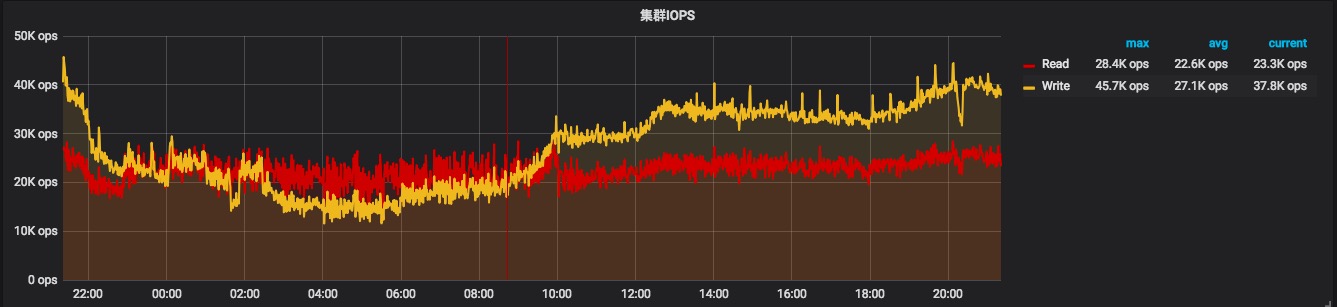
我们非常关注ssd磁盘的情况,所以针对ssd寿命的相关监控都有加上,看起来,集群流转写入一次大概会降低2-6%的擦写寿命,坏块很少,在擦写次数足够多的情况下,坏块几乎不会产生,具体要看磁盘本身体质,监控这些参数还能识别出ssd是不是二手盘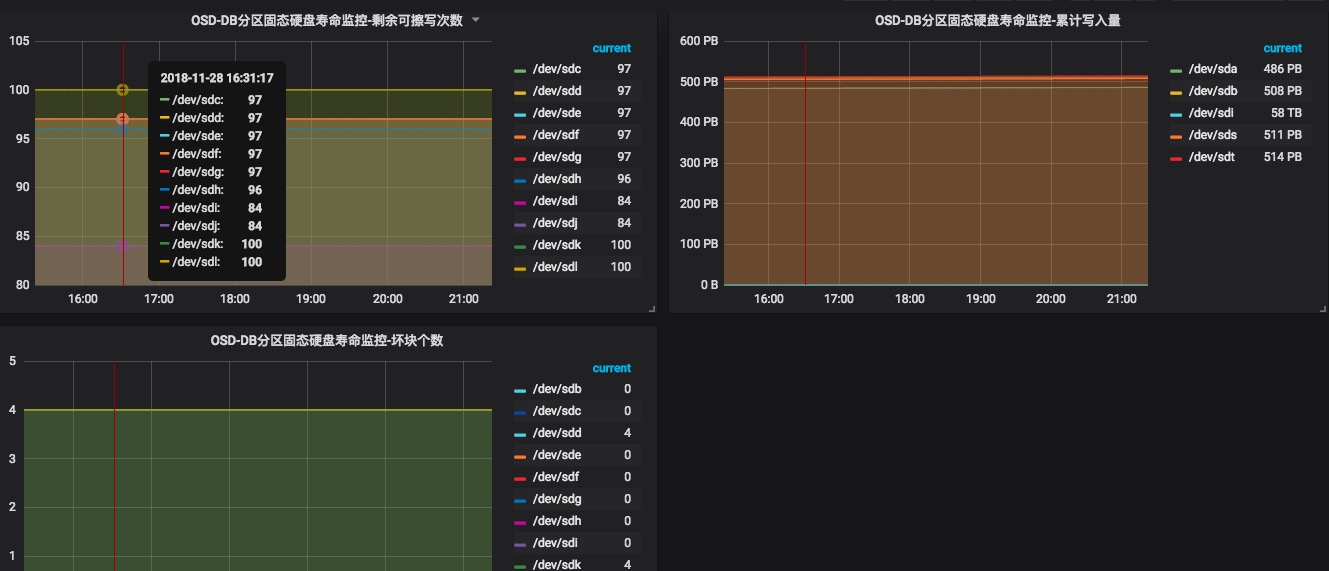
运维遇到的问题
osd异常重启
偶尔会出现osd重启的情况,经过排查,是ceph的bug,osd使用的tcmalloc会在某些情况下产生异常,导致osd异常重启,一个月下来有4个osd发生过该情况,不过osd起来后,很快就恢复了集群功能,最快一分钟就能恢复,告警甚至都还没有来得及触发;目前已经提交社区进行处理,笔者提的bug与其他人重复了#2352,大概要几个版本之后才能解决吧
bucket的shard动态修改
如果固定配置bucket的shard值,会导致bucket很不灵活,产生大量无效分片,于是我们设置一个定时任务,在每小时的59分进行计算,重新设定下一个小时的bucket的分片数,从prometheus监控效果看来还不错
总结
得益于ceph的稳定性,我们在线上使用一段时间以来,还算稳定,性能也还在不断优化,业内使用最新版本(接下来会上ceph-12.2.7版本)上生产环境的案例不多,我们还是逐步摸索地前行,面对日益增长的存储需求,还会有更多的调优和运维工作


- 本文作者: 奋斗的松鼠
- 本文链接: http://www.strugglesquirrel.com/2018/08/09/ceph存储三十亿个小文件的实践/
- 版权声明: 本博客所有文章除特别声明外,创作版权均为作者个人所有,未经允许禁止转载!